
Project Overview #
This project focuses on building a serverless, scalable data lake on AWS to collect, process, and analyze historical NBA game data. The pipeline is designed to automate the entire workflow—from fetching data to running SQL queries for insightful analytics.
By leveraging AWS-native services, the solution ensures cost efficiency, minimal maintenance, and flexibility to scale with growing datasets. It provides a centralized storage and processing layer, making it ideal for downstream analytics and visualization tools.
Architecture #
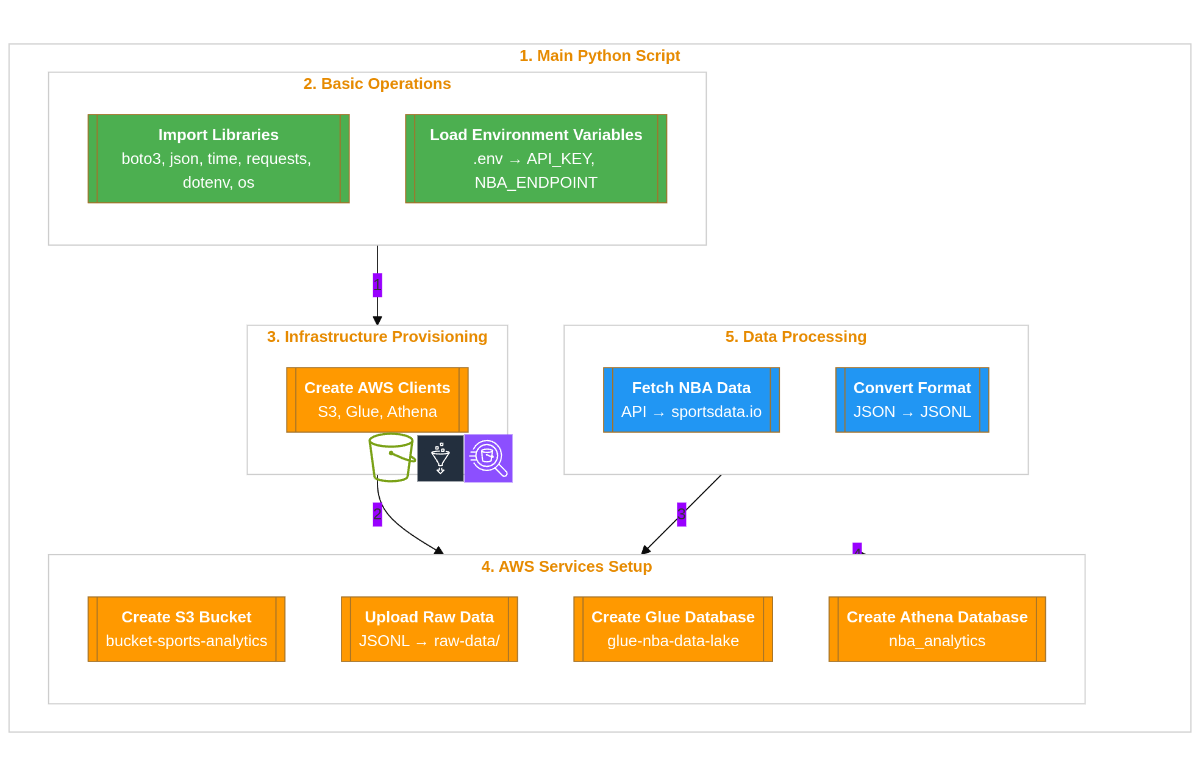
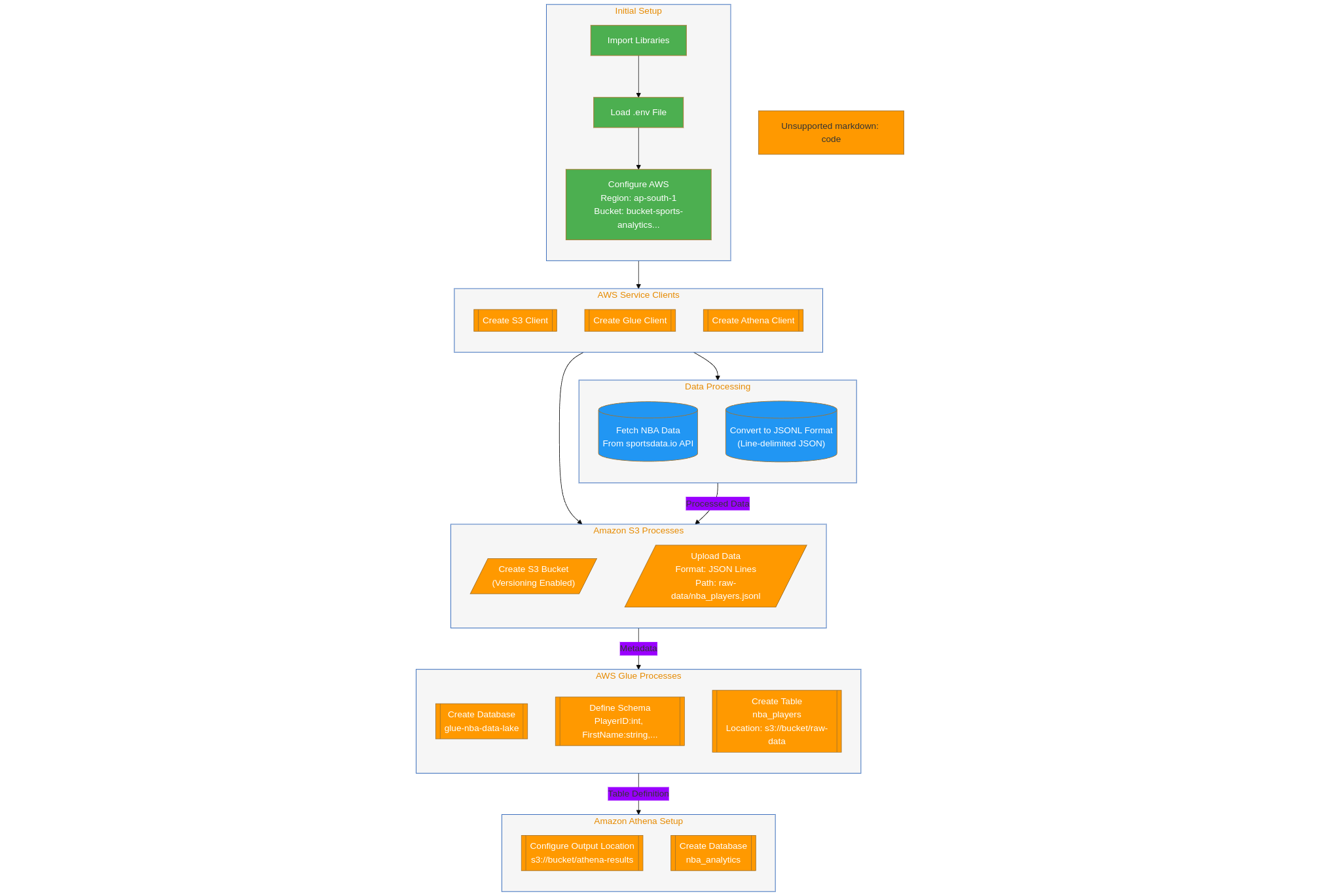
Hands-On Experience #
- Designed and deployed a complete data lake using AWS S3, Glue Crawlers, and Athena
- Automated data ingestion using Lambda functions triggered by EventBridge rules
- Used Python to transform raw JSON data into optimized Parquet format for efficient querying
- Scheduled daily jobs executions using EventBridge
- Implemented schema evolution and data cataloging using AWS Glue
- Queried large datasets using Athena with SQL for trend and performance analysis
Tech Stack #
- Infrastructure: AWS (S3, Glue, Athena)
- Programming: Python, Boto3 SDK
- Database/Query Engine: Athena (SQL)
- Execution: CloudShell
- Environment Mgmt: Python-dotenv
Project Links #
A sports analytics data lake leveraging AWS S3 for storage, AWS Glue for data cataloging, and AWS Athena for querying. Python scripts are used for data ingestion and manages the infrastructure.
Blog Post